The History of Automated Testing and TDD
Functional testing was popular at the beginning of computer science. Back then, individual functions were tested in isolation. In the 80s and 90s, object orientation “took the world by storm.”1. Testing shifted during this time to encapsulate object behaviors, but also became less popular as the world of software development changed.
In 1999, TDD, or test-driven development, was first introduced and widely popularized in the Java world by Kent Beck.
This began the movement of automated testing for modern software development. By mid-2000s, automated testing, or writing test code alongside your app code, became common. It has become the definition of high-quality in the software industry.
Separate camps pioneered automated testing:
(1) In Java, testing became popular at the turn of the millennium.
(2) At Google (launched in 1998), the early applications were primarily built with manual testing (not automated testing). Google Web Search (known to the rest of us as “google search”), was very buggy in 2005. At some point around this time, over 80% of production pushes contained user-facing bugs. 2
This instability was the central catalyst for a revolution at Google to bring automated testing to all code written at the company.
(3) Testing was baked in for the Ruby on Rails community, a framework Rails that first became widely popular around 2005. The incredible success of the second dot-com wave of the late 2000s/early 2010s era was built on the foundation of the Rails community’s value system and commitment to automated tested codebases.
Ruby developers were also instrumental in evangelizing TDD — or test-driven development. In TDD, the developer writes a test first, watches it fail, and then implements the feature to make the test pass. This continuous cycle — known as the “TDD loop” — provides these vital advantages over non-TDD development:
(1) As a design exercise, it exposes our code’s hidden dependencies and helps push us to write cleaner code. (It is one of many tools we use to push ourselves to write cleaner code. Better code in a TDD environment isn’t a given, but is significantly more possible than in a non-TDD environment.)
(2) Because a test suite harnesses the code, we have a solid way catch bugs and regressions quickly and early when introducing new features early in the dev process, not once they are already deployed to production.
(3) As developers, we don’t need to hold the entire app context in our heads while debugging.
(4) We can confidently refactor our code over time to make it more extensible and easier to maintain.
What are automated tests?
Automated tests come in various sizes and flavors.
Google considers test size to be the number of resources to run the test and test scope to mean the number of code paths executed. 3
There are various ways to look at testing, but for a broad overview:
Unit tests are the narrowest level of tests you can write. They are designed to validate logic in a small, focused part of the code, like an individual class or method.
Integration tests are designed to verify interactions between several components.
Finally, end-to-end tests (or system tests) are designed to validate the interaction of several parts of your system.
How many unit, integration, and end-to-end tests do you write? I’ll get to that later down when discussing Test Pyramids, but first, let’s discuss the virtuous TDD cycle.
Test-First Development and Red-Green-Refactor
As mentioned above, test-first development is when you move through a particular cycle:
- You write a test expressing the outcome or code you wish you had.
- You run the test to watch it fail. (“red”)
- You then implement just the amount of code needed to make it pass. (“green”)
- Once you’ve successfully implemented it to “green” (passing), you can refactor the code you’ve written, knowing the tests will make sure it continues to work.
When doing this, you repeat this cycle for each smallest increment or feature you can build. Thus, you never write either more test code than the smallest increment you are implementing, nor do you write more app code than what you’ve written a test for. This is called the Red-Green-Refactor cycle and is the holy grail of the test-first movement of software development.
To get a feel for what TDD looks like, take a break from this high-level explanation and take a look at an example using Java, the language where TDD began.
Example 1: Getting Started with Unit Testing for Java
Testing as a Design Exercise
Most people will say automated testing aims to “catch regressions and bugs.” Unfortunately, while it does have some truth, this argument falls short of the true benefit of testing. Testing is best understood as a design exercise. When we say “exercise,” we don’t mean simply something you do for practice . Instead, we mean something you do to maintain strength and flexibility.
That’s because good tests help you write a well-structured codebase. They force you to make design decisions that decomplect (make less interwoven) your code. They expose (show you) when your code is tightly coupled or abstractions aren’t working in your advantage.
Should catching regressions be a reason to write tests? Yes. But it isn’t the primary reason to write tests. The primary reason to write tests is a tool (exercise) to write decoupled code and to expose hidden coupling in your objects or modules. That’s why we say testing is a design exercise.
Black Box Testing
When testing code, you want to be clear about what is being tested, also known as the “system under test” or SUT. Importantly, you want to treat the code being tested (for example, a class) as a black box. You give ‘the box’ inputs and assert some expected output. What you never do is test how the black box did its job. It’s called a “black box” because you can’t see inside it, and your tests aren’t supposed to peak inside it either.
The Golden Rule of Testing
The golden rule of testing is:
Test behaviors not implementation details.
This means that, as described in “black box” testing, you don’t test the internals of how a module or object implements something. Instead, you test against the behavior of the app code. Specifically, focus on testing the behavior of the app code as defined by the business itself— so your test explicitly discusses who, what, where, when, and why.
What is Hermetic testing?
Hermetic testing means that the test contains all the data necessary to run the test. This includes sample (‘mock’) data, the setup of conditions necessary to run the test, the test assertions themselves, and any teardown that is run after the tests. The test steps and setup don’t live off in other files that are difficult to find, and the setup doesn’t depend on information in places or parts of the codebase that are frustrating to see if you don’t know about them.
Hermetic testing also means that the test doesn’t leave a state behind that would affect other tests (for example, database records left in the database, which might affect the next test.) This is how we know one test doesn’t affect or depend on another. Thus, the tests are hermetic.
The whole test file expresses all the conditions the app will need to be in to run the test, and once it runs, it also resets the state of the app back to the state where it started, making it safe for the next test to run.
If you don’t write hermetic tests, your tests will have external dependencies (that means they depend on parts of your code somewhere else in your project.) External dependencies might include things like seed data hidden away in obscure files, data constructed in ways that are not easy to see, or test helpers containing too much business logic.
The code you are testing is called the target code, also known as the “system under test” or sometimes just called app code. (All three names mean the same thing.) The tests you write— written in code and typically but not always in the same language — are called test code.
If small changes in the structure of your app cause many of the existing tests to break, or you are afraid to make changes because you might break tests, you have what’s called “brittle tests.”
An app that suffers from these maladies probably has too many tests that are not hermetic or is coupled to parts of the system that should be decoupled. Keep the setup and teardown logic inside the test you’re writing, and always use factories or factory-like patterns to set up your test data.
Factory Testing
In a factory, something — like a tangible product— gets reproduced repeatedly. You can make many of the same things on the factory line.
Like a factory line, factories in software produce the same object over and over again. Using factories and keeping our tests hermetic, we can ensure a consistent and smooth testing process.
A factory defines the basic instance of a thing we are testing — like an invoice, a book, a subscription, or a user. Here, we might build a “user” object using a Ruby factory like so:
FactoryBot.build(:user)The user factory itself is defined in the factory file:
FactoryBot.define do
factory :user do
first_name {“Bob”}
last_name {“Smith”}
timezone {timezone("Europe/Athens")}
end
end Every time we call FactoryBot.build(:user), we get a user object created on-the-fly with this data. If, for example, we want to create a user with a different name, we’d use this in our test:
FactoryBot.build(:user, first_name: "Jane", last_name: "Doe")
Here, we use the same factory but override first_name and last_name. This makes factories so powerful: The test code can describe the specific attributes different from the default factory data, and the factory will use the default data for anything unspecified. Why is that so powerful? Because now, our test communicates why this use is special or different from the default factory.
Unit Testing
Unit tests test a discrete unit of functionality. They:
- are small
- are fast
- are deterministic (get the same result each time you run it)
- are easy to write
- serve as documentation
- show the code under test (“system under test”)
- convey how this code is intended to work
Various themes that are important to know about in the field of unit testing your app code include:
Maintainability
Test maintainability is challenging to quantify, but it is easy to see the reverse: the anti-pattern (the thing you should not do) of tests with poor maintainability. You can recognize a codebase in this state because:
- It’s challenging to figure out what the tests were doing in the first place.
- It has hacks that make the tests more difficult to understand in the future.
- Fixing these tests feel like a burden.
Brittle Tests
Brittle tests are tests that break in response to harmless or unrelated changes. Typically, you know a test suite is brittle when many little tests break but do not introduce any real bugs.
As a codebase grows with brittle tests, a larger and larger proportion of time must be spent fixing them. This is an anti-pattern; brittle tests should be refactored out of your test suite. Better yet, use test refactoring as a design process to drive toward de-coupled design.
Unclear Tests
You know a test is unclear if it meets this criteria: After breaking it, it is difficult to determine what was wrong or how to fix it.
Tests should be expressive of their intention. That is, when you or another developer reads it, it should be immediately clear what the purpose and value of the test is. Ideally, the actual test name itself is so cleanly written that it communicates everything the next developer would need to know about the test.
Flaky Tests
A flaky test is a test that fails non-deterministically. In other words, it doesn’t pass or fail consistently (non-deterministic). Non-deterministic tests fail for a variety of reasons. Most typically, these fail because of race conditions. Any randomness in the app or the randomized order of the test run can also cause flaky tests. As well, time-of-day/time-of-month — known as time-sensitive conditions — could cause the test to fail when those conditions aren’t met.
A non-deterministic test might fail on your local machine but pass on CI, or vice-versa. They might fail randomly or just on the first Tuesday of the month. (Arguably, a date-based failure is technically deterministic but can be grouped in with flaky tests as such tests are mistakes that should be taken out.). Flaky tests are some of the most challenging problems in developing a modern test suite, so you should avoid introducing them whenever possible. When you find them, work to remove the flakiness from the test.
A “Pure Refactor”
It’s easy to ‘refactor’ and change behavior without strict TDD. That is, implement small changes as we refactor. Strictly speaking, this is not TDD because you aren’t driving every addition using a test. Technically, ‘refactoring’ means not adding or removing, just changing the implementation details. But the meaning has been watered-down to include activity that refactors and changes behavior. That’s why the term pure refactor is used to distinguish specifically changing implementation without adding or removing behavior in contrast to a muddy refactor, where you both change the implementation and add or remove features simultaneously (not following the ‘strict TDD’ paradigm).
Tired of all this high-level theory? Take a look at A Pure Refactor with Python, which is example #2:
EXAMPLE 2: A Pure Refactor with Python
Continuous Integration Running on Github Actions (or the CI of Your Choice)
Continuous integration means that you attempt your best to write your code in small, iterative steps. Ideally, you won’t have long-running branches. To achieve this, your test suite should be fast, and guardrails should be in place to ensure that you or any devs on your team don’t accidentally check in the code that breaks the tests.
There are many choices for “CI runner,” which is the external service you will use to run your CI suite. You can configure your GitHub Workflows in Github to run on all pull requests, and all commits.
When your repo uses a merge strategy, notice that there are two runs of the CI: 1, the pull request run, which runs against the merge commit (the commit that will happen if you make the merge) and 2, the push run which runs against the HEAD of the branch (marked pull_request and push by Github Actions below).
This distinction is important when your repo uses a merge strategy because one might fail, and the other might pass, depending on the upstream changes. (If you use a rebase strategy, this does not apply to you.)

Although GitHub CI is an easy and familiar choice, it has some downsides and there are many, many choices.
Other continuous integration alternatives include CircleCI, Semaphore, Gitlab, Bitrise, Flosum, Buddy, Gearset, Copado, Jenkins, Codefresh, AWS Codebuild, Azure Pipelines, Provar, and Travis CI.
A note about the term “continuous integration.”
Originally “continuous integration” meant that you were both running your test suite and deploying to production continuously. Now, the meaning of “CI” has changed, and people use the term to refer to external services like the ones listed above. In modern colloquial software teams, “CI” refers to the mechanism used to run the tests on both the branch and the branches (pull requests). The original meaning of “continuous integration” described a working style where you didn’t make branches whatsoever and continuously added to the main branch, keeping your tests passing commit-by-commit.
Test Pyramids, Trophies, Ice Cream Cones, and Hourglasses
In the field of automated testing, there are three basic types of tests:
End-to-end tests (system tests) validate the interaction of multiple parts of your system.
Integration tests where we verify multiple components working together
Unit tests narrowly cover our small code units — typically business logic . When writing a unit test, you test only the code that’s part of the “system under test” (SUT).
(In Typescript and strongly typed languages, the compiler provides a layer of static testing below the unit tests.)
The most famous metaphor can be attributed to Mike Cohn from his book Succeeding with Agile, in which he coined the term “Test pyramid.” In this most basic example, the unit tests comprise the vast bulk of your tests suite, followed by integration tests and just a few end-to-end tests at the very top.
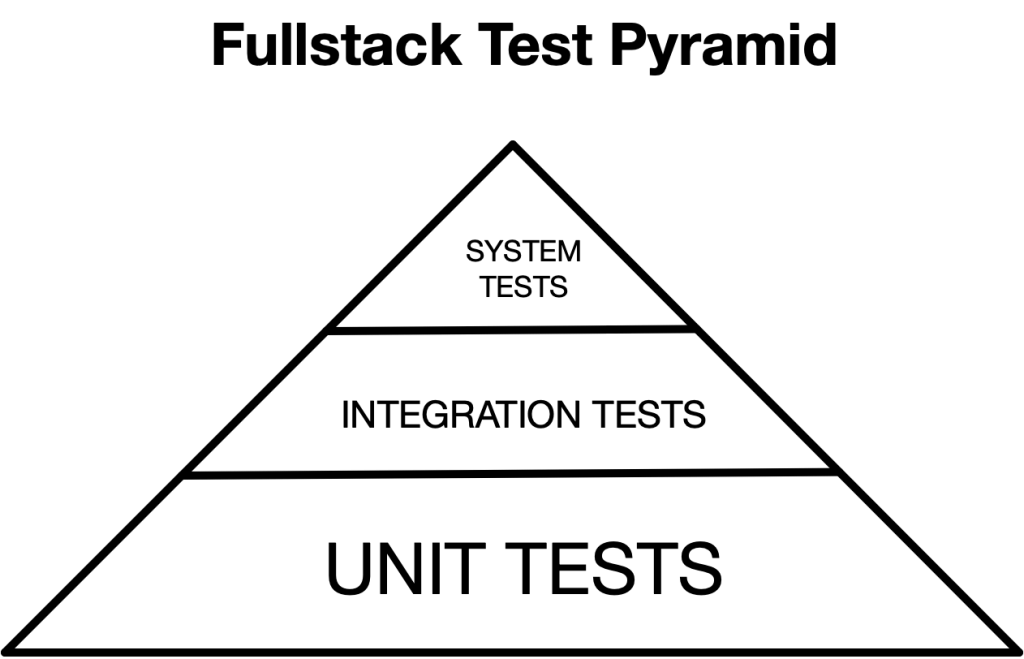
The common explanation of why this is is that the system and integration tests take longer to run . So unlike the very fast unit tests, you don’t run the whole system test suite all as you develop code (you just run it during your continuous integration build). Of course, you can run the system and integration tests locally as you develop your code (and should learn how)— you just typically don’t run the entire suite of system tests because it would take too long.
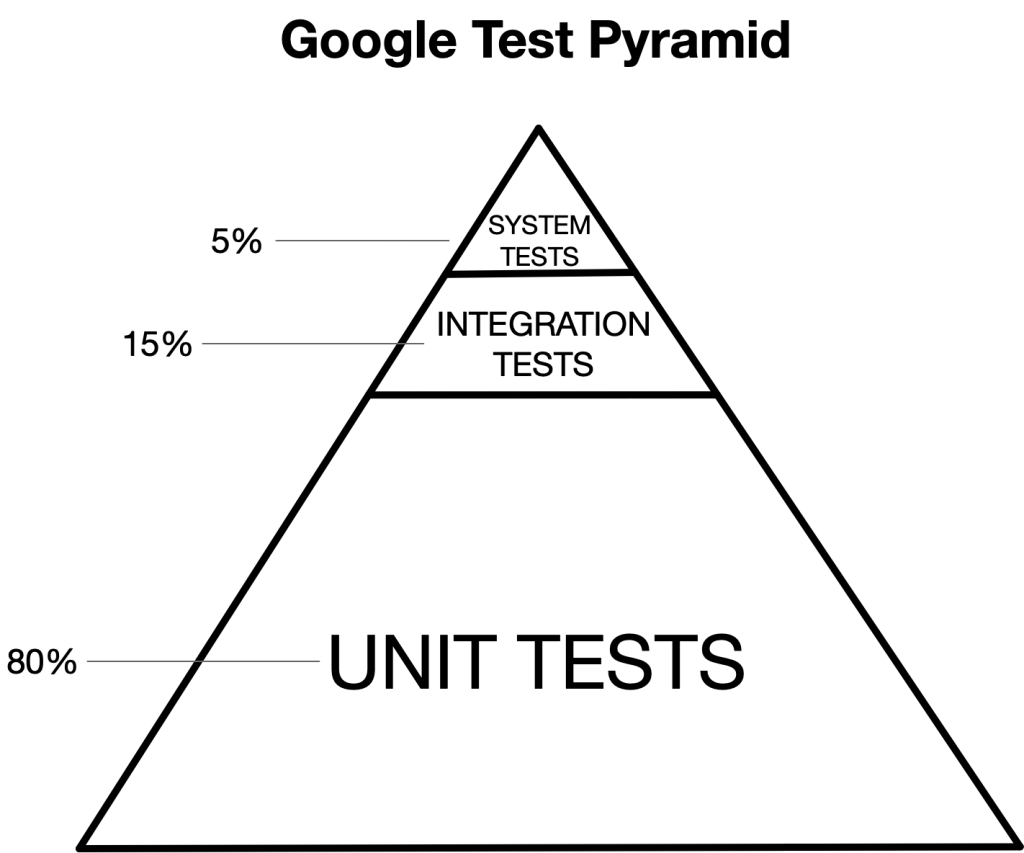
At Google, the author Adam Bender suggests it is common to talk about using an 80%/15%/5% interpretation of the Test Pyramid metaphor, but this is just a rough estimate.5
The Google pyramid might look a little more like this (proportions of this triangle are drawn approximately).
Over in the React world, Kent C. Dodds pioneered what he calls the testing trophy. 6

from top to bottom:
- And a tiny bit of end-to-end testing at the top.
- A bulk of integration testing to test how components interact with one another
- A basic (small) amount of unit testing
- Static type checking for a strongly typed language catches your first layer of type errors
Testing Hourglass
We typically talk about the hourglass pattern for server-rendered apps: heavy on unit + heavy on system tests but light on integration tests. (That is, you write integration tests only when there is no other feasible way to test the stack the full-stack or if you have a lot of middleware or intermediary business objects).
But remember that this is contextual to traditional MVC architecture, which emphasizes business logic in either models or BO (business operation) objects. The whole stack is tested with end-to-end system tests (the most valuable kind in web development). Most traditional MVC apps don’t (or shouldn’t) have a lot of middleware code, so they don’t need a lot of integration testing. The more middleware code you have, the more integration testing you want.

You write fewer integration tests and more end-to-end tests because the tests in the middle are typically seen as less valuable. However, it is widely accepted that end-to-end tests are costly, so they take a lot of developer time to write and maintain. The general idea is that you want fewer high-value tests and a blanket of unit tests. But be careful about the idea of “blanket unit tests” — most of the time, the unit tests are less valuable than people think at catching regressions (more on that below), but they are essential when upgrading your libraries (Gems, Node packages, etc).
The Ice Cream Cone Antipattern
Many experienced testers talk about the inversion of the pyramid as an ice cream cone and add the ice cream as the manual testing that must be done at the top end of the cone. (This is an anti-pattern or something common but not useful.)
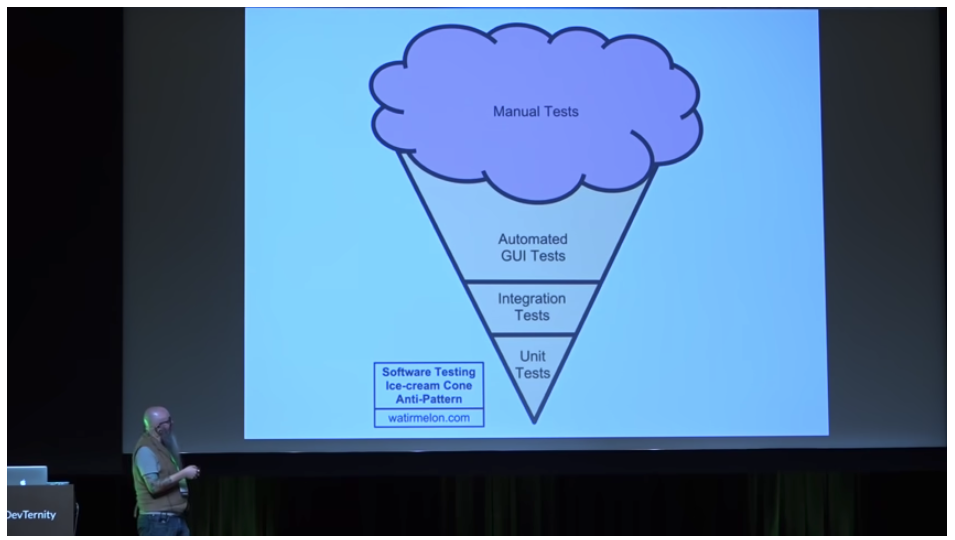
Don’t do this!
…
…
…
…
…
…
…
These are metaphors, but it’s important to note that even the best dev teams can have lopsided test suites.
Your mileage may vary — of course — but aspiring software engineers need to ground themselves in a solid understanding of these discussions and proactively have these discussions with their team.
The “Arrange, Act, Assert” Pattern, Gherkin-style BDD, and “Story Form”
“Arrange, Act, Assert” is a pattern where you write your lines of test code in three parts: First, the code in the Arrange section sets up the test expectation as prerequisites. The Act does the action that will invoke the system under test, and the assert asserts the business behavior we are testing.
You will often use a before or setup method to set up your Arrange, although there is no hard rule you must. You can follow this pattern simply by using spaces to separate your Arrange-Act-Assert lines.
Martin Flowler coined the term “Given When Then, ” a variation on the same idea. 8
You set up your expectations by writing code that says “Given ____ ” The action is made inside of a “When ____” declaration and the thing you expect to happen is specified by “Then ____ ” Typically, this is the exact language that the test mechanism uses. (The language of your test code.)
This is also called Gherkin-style syntax and behavior-driven development, where BDD focuses on user behavior more precisely than component integration.
In particular, there was a time (around 2009-2012) that a tool called “Cucumber” testing was used to write tests on two levels — one, a higher level product requirement style that was supposed to be read by the stakeholders, and, two, a lower level implementation details level. This idea that product managers or stakeholders would read or write high-level tests in an English-like syntax was touted by the BDD community for years, and although it was theoretically a great idea, in practice, stakeholders never actually read, wrote, or cared about Gherkins, so this style was largely abandoned. However, it did help the testing community get grounded in thinking from the customer perspective, which remains one of the core skills you will need as a tester.
High Value, Low Value, and Negative Value Tests
One of the most complicated things to grok in your journey to be a TDDer is that not all tests are equal. Tests that are not tightly coupled to the implementation, follow the product requirements, and provide real value are called high-quality (or high-value) tests.
Many tests are too tightly coupled to implementation or infrastructure architecture. As a result, a slight change in your code can lead to many of your tests breaking. Although sometimes unavoidable, these kinds of tests are typically worse than having no tests at all.
Of course, the line between a ‘low value’ test and a ‘negative value’ test might be subjective, but what’s important is how much they help you reduce completing (interweaving) in your codebase while also making the development smooth and stable.
TDD Is Dead
In 2014, David Hanenmier-Hansen famously wrote a short blog post titled “TDD is dead. Long Live Testing.” 9 He begins his essay by saying test-first fundamentalism (or a neurotic insistence that you always write a test first) is “like abstinence-only sex ed: An unrealistic, ineffective morality campaign for self-loathing and shaming.” He wrote that whatever good was originally intended by TDD, it had been corrupted by a cadre of “mean-spirited” test fundamentalists who try to shame people for not strictly writing tests first. (Always writing a test first is explained above as the virtuous TDD cycle.)
DHH’s backlash against TDD is justifiable — a neurotic need to always write tests first, and an industry that overemphasized unit testing, in particular— had led to a scenario where we had overemphasized unit testing.
One facet of DHH’s backlash against the TDD mantra is very technical and specifically relates to how Rails ActiveRecord works. The “model” files are tightly coupled to the database, meaning when you create or save a model object, it creates or saves it into the database. The purist TDDers told him that meant he was doing testing wrong because 1) it means your tests will run slower because of all those database transactions, and 2) it means your models are tightly coupled to their database transactions.
So for DHH, he doesn’t like the purists. Instead, he lets his tests “hit the database” directly.
Why Most Unit Testing is a Waste
In his paper “Why Most Unit Testing is a Waste,” 10 James Coplien discusses several important advanced topics of testing anti-patterns and how coding teams can have too much faith in their unit tests.
He starts with a simple posit: if a test never fails, it has little value. (If it always fails, it also has very little value.) He reminds us of the two-pronged nature of testing:
There are two potential goals in testing. One is to use it as a learning tool: to learn more about the program and how it works. The other is as an oracle. The failure mode happens when people fall into the latter mode: the test is the oracle and the goal is correct execution. They lose sight of the fact that the goal is large insight, and that the insight will provide the key to fixing the bug.
Coplien, James, “Why Most Unit Testing is a Waste 11
By “oracle,” he means that the test is supposed to speak the truth for the business and that the test code is somehow more sanctimonious than the app code. This leads to the overuse of unit testing to provide a feedback cycle that gives you false security. It gives you false security because, for example, you’ve covered every line of code with nearly 100% coverage. Still, you haven’t made correct assertions protecting the business requirements from breaking. This is the primary testing antipattern Coplien is discussing.
He boldly suggests throwing away any regression test that hasn’t broken in a year. It may sound drastic, but what he’s saying is that all tests have a cost: a cost of maintenance, a cost of cognition, and a cost to run in your test suite. If the test never fails, it provides little value, perhaps even negative value.
Like most advanced testers, Coplien advocates for a smaller number of high-value system and integration tests rather than a larger number of low-value unit tests.
Just because tests can help you write cleaner code doesn’t mean they automatically will. Coplien points out that using the requirement to have code coverage leads to writing more confusing and obfuscated code to achieve cleaner or closer to 100% coverage reports.
Some additional points he makes can be summed up as:
• Good testing does not take away your responsibility to think critically and think about the system as a whole.
• If you can cover a business requirement with a higher-level test vs. a unit test, start with a higher level (system or integration) first.
• “If the test fails, what business requirement is compromised?” If the answer is “I don’t know,” that test is probably low-value.
• A high failure rate means you should shorten development cycles (make smaller branches/work in smaller iterative steps).
• Be humble about what tests can achieve. “Tests don’t improve quality: developers do.”
Snapshot Testing & Shallow Testing
Snapshot testing is when you give your code some inputs, record its complex output, and put it into your test code directly. Although not fundamentally different from other forms of testing, it is a lazy option that doesn’t involve asserting against behavior. Generally, snapshot tests are brittle (break with seemingly unrelated changes) and so are low-value.
Shallow testing is when you test UI components in extreme isolation — like React DOM testing — and make assertions against only basic UI input & outputs. Shallow testing means we have a piece of code with dependencies, but we aren’t testing those dependencies. Shallow testing is also low-value testing.
What are ‘Contract Tests’?
A contract test, or API test, is when you test a component of your application for how it will talk to an external service or set of services. You will mock or double the calls from your code to the external service and then make assertions against those mocks. The test will snapshot a specific set of parameters/data/interaction between your code and the external service. It will form a contract between that service — often called a ‘consumer’ — and your code.
Mocking, Test Doubles, Mocks, Stubs, Spies, and Fakes
Five mysterious characters appear in advanced testing. Although this is too much to cover in this overview, I’ll briefly introduce these advanced topics now: test doubles, mock objects, stubs, spies, and fakes.
Mocking is an unfortunate umbrella term for all the other things listed: doubles, mocks, stubs, and spies. On a very technical level, a mock object is one very specific tool used, so the problem is that people don’t learn the nuance of these different tools and just call them all “mocking.”
In Martin Fowler and Gerard Meszaros’s terminology12, test double is a noun you can use to refer to all of these options. (“Mocking” is used lazily as a verb to refer to all of these tools, but do not confuse “mocking” with a “mock object,” which is just one of the five specific tools.)
A test double is an object that can stand in for another object during the test.
A mock object defines an expectation for how the object will be used.
A stub is when we provide fake data — or a ‘canned answer’— for the code being tested. You do this when you can’t control or don’t want to include where the data comes from.
A spy is a stub that records information about what messages the object receives or how it was called and may have assertions against it. (As in contract testing.)
A fake is when we partially implement an object for testing purposes but not for production code.
As mentioned above, the general rule is to avoid all of this (doubles, mocks, stub, etc.) for code you own when pragmatic.
For your unit tests, you will find a balance between touching objects not under test and mocking & stubbing.
You want to mock or stub the code you don’t own (like in someone else’s repository or for external services like APIs).
For integration tests, you need to carefully understand what pieces you are testing together and use the above tools to test only those interactions and mock or stub everything else.
For E2E (end-to-end) or system specs, you generally don’t want to use these tools unless you have no other options. (Except for mocking external web requests, which is still a good idea for system tests).
10 TDD Sane Defaults For All Projects
Your team or management should adopt a set of “sane defaults” at the start of your software endeavor. This includes processes, tooling, development & deployment workflow, and testing architecture. Here’s a basic suggestion of 10 sane defaults for any project:
- Keep your tests hermetic: When glancing at the test, the setup data should be easily exposed or findable (either at the top of the same test file or in neatly packaged factories.) You shouldn’t have to go to several different files or do significant debugging to understand the test or to find the setup data— it should all be in one place, the test file itself. (I prefer using factories over fixtures, see #8 below.) Another facet of being hermetic is that the test doesn’t depend on global state set up before it runs and doesn’t leave any global state behind it after it runs. For this reason, always have a teardown (or after) method that does the opposite of the setup (or before) method, so that the global application state is left in the same way it started after the test has run.
- Always focus on the target of the test. Know if you are writing a unit, integration, or system test. A unit test? Use mocking & stubbing to stub out only code that 1) code you don’t own and 2) is not the target of the test (i.e. exists in a class or object outside of what is the target of your test.) For integration tests, always focus on the interactions between components. Your focus should be on high-level user interactions and product requirements for system tests.
- Tests should be expressive, targeted, and purposeful. They should clearly and cleanly express the intention of the test up front and match the product requirements they were created from. Roughly, the name of the test should match the product requirements written by the product owner. (For an introduction to how to write compelling product stories, see this post.) If a test doesn’t meet these criteria and its purpose cannot be easily understood, it should be identified as a low-value test and be removed.
- If a test is flaky (fails randomly on some runs, whether or not you made any code changes), it should be made less flaky or removed.
- If a test is brittle (fails for seemingly unrelated changes), it should be made less brittle or removed.
- Use testing to expose poor design decisions. You may find yourself mocking too much. That means your code has too many dependencies, and you should use dependency injection to decouple parts of your codebase. See and understand testing primarily as a design exercise and secondarily for regression catching. Other reasons to test are so you don’t have to keep the whole context in your head and to push you towards writing cleaner code.
- Avoid snapshot testing and shallow testing. (Snapshot testing is reasonable as a last resort when you have no other good options.)
- Prefer factories over seeds or fixtures. (There are good reasons to use fixture data sometimes, but try avoiding this when possible.)
- Continuous integration runs on every commit and every PR. Note the difference between running on the “pull request” and running on the “HEAD commit,” explained above. Some CI runners can stop running the test when you push a new commit. Although it can save you a little money, I recommend against this option because the valuable part of the CI runner is seeing exactly which commit was introduced that caused which test to fail. If you stop your prior builds when pushing new commits, your CI runner’s interface becomes less valuable because it can no longer show you that. Of course, some teams or solo devs might deviate from this, but the point is that you shouldn’t wait until the very end of your pull request to run your tests — you should run them continuously as you develop and ideally not check-in code that breaks tests at all.
- Use testing and TDD to identify complected code (intertwined concerns) and de-complect as you refactor.
I hope this brief introduction to testing and TDD helps set the stage for you to get a broad overview of the important topics in automated testing. To get started, I suggest you go through a TDD tutorial for the common TDD tool for your language: For example, I’d recommend:
• Jest for React/NextJS (also Cypress for end-to-end testing)
• Rspec for Rails (also Capybara for end-to-end testing)
• PyTest for Python
• JUnit for Java
• Cargo’s built-in unit testing framework for Rust
Footnotes
- Coplien, James, “Why Most Unit Testing is a Waste,” https://rbcs-us.com/documents/Why-Most-Unit-Testing-is-Waste.pdf
- Bender, Adam, “Testing Overview” from Software Engineering at Google Winters, et al
- Bender, Adam “Testing Overview”, from Software Engineering at Google, Winters, et al (2020) pp. 215-217
- Cohn, Mike (2008). Succeeding with Agile
- Bender, Adam, “Testing Overview” from Software Engineering at Google, Winters, et al. (2020). Software Engineering at Google, 220.
- Dodds, Kent, “Testing Trophy,” https://kentcdodds.com/blog/the-testing-trophy-and-testing-classifications
- Cooper, Ian, “TDD Where Did It All Go Wrong” https://www.youtube.com/watch?v=EZ05e7EMOLM
- Fowler, Martin, “Given When Then”, https://martinfowler.com/bliki/GivenWhenThen.html
- Hanenmier-Hansen, David, “TDD Is Dead Long Live TDD”, https://dhh.dk/2014/tdd-is-dead-long-live-testing.html
- Coplien, James, “Why Most Unit Testing Is a Waste,” https://rbcs-us.com/documents/Why-Most-Unit-Testing-is-Waste.pdf
- Coplien, James, “Why Most Unit Testing is a Waste,” https://rbcs-us.com/documents/Why-Most-Unit-Testing-is-Waste.pdf
- Fowler, Martin, “Test Double,” https://martinfowler.com/bliki/TestDouble.html